ここではPyhtonの文法基礎を勉強して、ファイルをマイドライブにアップしてそのファイルをコードで読み出します。さらにデータから平均値などを計算したり、グラフをプロットするモジュールをインポートします。Pyhtonの初級文法を学修しましょう!
目次
- Colabで四則演算
- 変数を使った計算
- インポートしたモジュールを利用
- マイドライブのデータを読み出す
- 数値計算
- グラフのプロット
- データの型
- 条件分岐[IF]
- 繰り返し[forとwhile]
- 関数の定義と利用
- データの型[リストとタプル]
- GPTでプログラミング
1. Colabで四則演算
「ファイル」にカーソルを合わせて表示されるプルダウンメニューからノートブックを新規作成を開きましょう。
※ノートブック(Notebook)は実は、Pythonのもう一つの環境であるJupyter Notebookに似ています。
新しいページが開いて、下図のようなコード(プログラム)を入力する枠が表示されます。

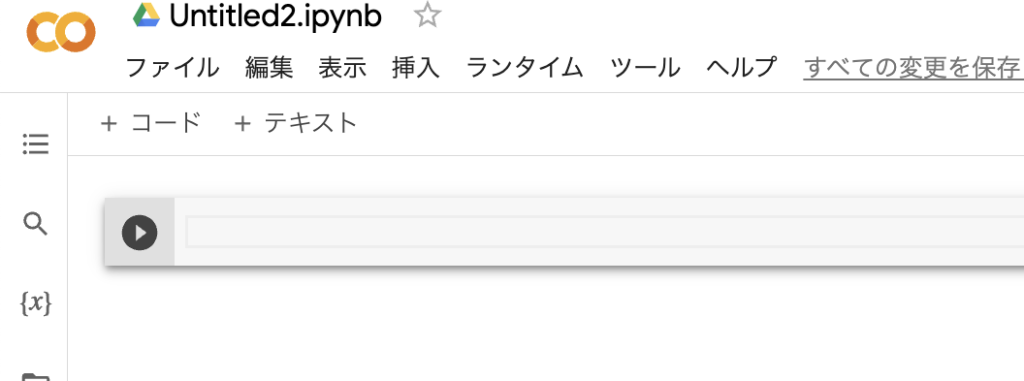
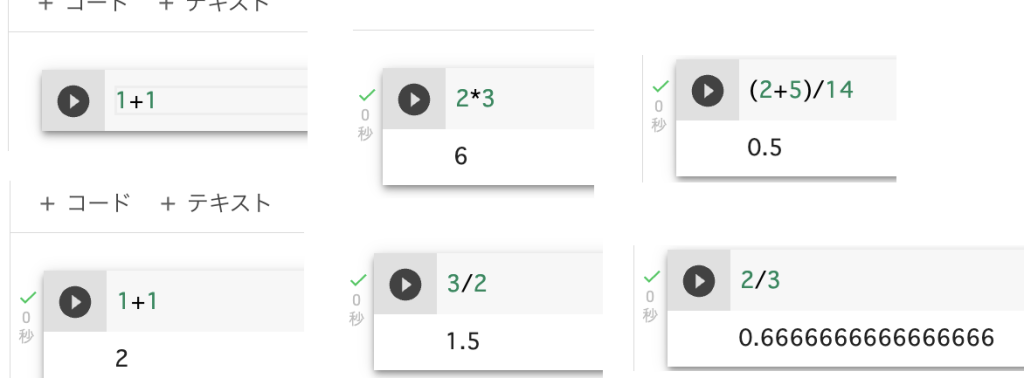
コードを入力枠に「1+1」などの数式を入力して左の三角(▶)をクリックして計算をするとコードの下に回答が表示されます。図のように計算できるか確認してください。新しいコード入力を行うにはファイルの下にある「+コード」をクリックすると新しいコードを出ます。
2. 変数を使った計算
colabにログインした最初のページの説明で次の式がありましたね。Pyhthonでは変数を簡単に「x = a + b」の形で定義できます。
seconds_in_a_day = 24 * 60 *60
もっと簡単にa=10, b=20としてx=a+bを計算させxを出力すると30が計算されます。
a = 10
b = 20
x = a + b
x
→ 30
3. インポートしたモジュールを利用
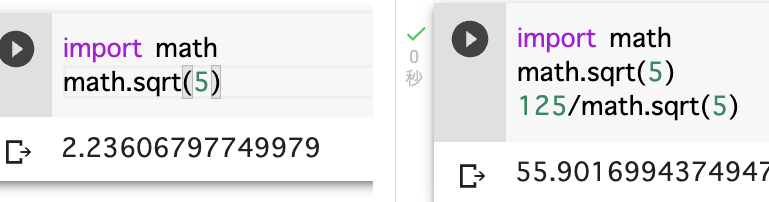
それでは次はモジュールをインポート(読み込む)してみましょう。モジュールとはプログラムのセットです。Pyhtonには沢山のモジュールが公開されています。先に挙げた機械学習のtensorFlowも公開されているモジュールの一つです。ここでは計算モジュールのmathモジュールをインポートして、平方根(ルート)を計算してみましょう。mathの後に、平方根(squre root)の記号sqrtを付け、「math.sqrt()」とします。モジュールの後のピリオドに続いてモジュールに含まれる機能を付けます。
ノートブック内では一度モジュールを読み込むとずーっと使えます。一度ページがリセットされると再度インポートする必要があります。
4. マイドライブのデータを読み出す
再度マイドライブをマウントします。Colabの新しいコードの欄にコピーして右の▶︎をクリックして実行してください。
from google.colab import drivedrive.mount(‘/content/drive/’)
- google driveのマイドライブの下にあるColob Notebooksを開いてください。以下のリンクからcsv形式のデータをdownloadしてgoogle driveのNotebooksのフォルダに入れておきます。
以下のデータをdownloadしてください。
excel_tutorial_data_sheet1.csv
ダウンロードしたファイルをColab Notebooksに移動してください。(downloadホルダーからドラック&ドロップで)
5. 数値計算
それでは、マイドライブ(google drive)のColab Notebooksのフォルダにいれたデータを読み込んでみましょう。先ほどのコードでColab Notebooksフォルダにいますね。従って新しいコードを開いて以下のコマンドを実行すると、入れたファイルの名前が表示されるはずです。
!ls *.csv
以下のように出力されるはずです。
excel_tutorial_data_sheet1.csv
次にデータをcolabで読み込んで内容を表示しましょう。pandasやmatplotlibはすでに学習しましたね。わからなければ復習しましょう。pandasはデータ解析用モジュールなので平均や標準偏差などの計算もできる。
import pandas as pd
import matplotlib.pyplot as plt
#CSVファイルをUTF-8形式で読み込む
data = pd.read_csv(‘excel_tutorial_data_sheet.csv’, encoding = ‘UTF8’, dtype = {‘No’:’object’, ‘A’:’float’, ‘B’:’float’, ‘C’:’float’})
#dataを出力
data
※ここで、read_csvの中でdtypeを指定します。Noの下は文字(object)として、A, B, Cは数値として(float:不動小数点)を指定しました。
このコードを実行すると以下のような表が表示されます。
dataという変数にcsvファイルを入れて、dataの中身を表示します。
以下出力見本
A B C
0 165.0 177.0 177.0
1 172.0 159.0 168.0
2 188.0 182.0 183.0
3 185.0 177.0 176.0
4 174.0 195.0 172.0
5 170.0 181.0 168.0
6 162.0 179.0 175.0
7 168.0 173.0 182.0
次にこのデータの平均値と標準偏差を求めます。平均値や標準偏差を求めましょう。data.mean()で左の結果、data.std()で右の結果が表示されるはずです。
data.std()を実行するには前の「#」を消して実行すればOKです。ただし、2行あると最後の行のコードだけの結果が表示されるので注意してください。
また、csvにある数字は整数ですが、平均値・標準偏差は小数点がつくので不動小数点(float)になります。このためwarningが結果の前に表示されますが、気にしなくて結構です。
data.mean()
#data.std()
結果の出力:
Class A 173.000
Class B 177.875
Class C 175.125
dtype: float64
さらに、以下のコードを実行すると四分位範囲も出してくれます。
data.describe()
A B C
count 8.000000 8.000000 8.000000
mean 173.000000 177.875000 175.125000
std 9.180725 10.020515 5.667892
min 162.000000 159.000000 168.000000
25% 167.250000 176.000000 171.000000
50% 171.000000 178.000000 175.500000
75% 176.750000 181.250000 178.250000
max 188.000000 195.000000 183.000000
6. グラフのプロット
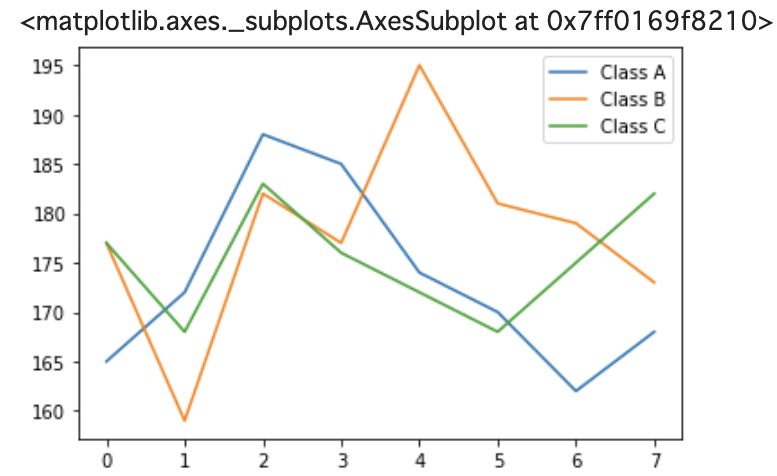
次に読み込んだ変数dataからグラフを作ります。matplotlibをすでにインポートしているので1行でグラフができます。
以下のコードを実行するとdata.plot()で折線グラフができます。上の「データサイエンスのページ」で説明したようにグラフにタイトルなども加えることができます。
#data.info() #データの様子を調べる
#data.describe() #データ統計量を調べる
data.plot() #データをグラフ化する(折線グラフ)
#data[“B”].hist(bins=10) #”B”で指定されたデータのヒストグラムを作る
#data.plot(kind=”bar”) #データをグラフ化する(棒グラフ)
6 データの型
データには文字データ(text)/整数(integer)/不動小数点(float;小数点のある数値)などがあります。多くのプログラムではこれらを区別するために、変数を利用するときに定義が必要です。Pythonでは「変数=」で整数を入れると変数は整数型として定義されます。
①hensu1=125 →hensu1は整数(integer)
②hensu2=12.5 →hensu2は不動小数点(float)
③hensu3=”文字” →hensu3は文字列
数値がどんな型かを調べるコマンドが「type()」です。コードに以下を入力して実行すると下にそれぞれのtypeが表示されます。コードに①〜③を入力して以下のコードを実行しましょう。→で示される結果が出力されるはずです。type(hensu1), type(hensu2), type(hensu3)
→(int, float, str)
8. 条件分岐[IF]
条件分岐の基本は大きい、小さいの判断です。コマンとしていは英語のifが利用されます。ifの後に条件の指定をして、それ以外はelse(そのほか)を使って記述します。
ここではprint()コマンドを使って判断の結果を文字で出力しています。
a=1
b=10
c=0
c=a+b
if c > 10 :
print(“cは10より大きい”)
else:
print(“cは10以下”)
→cは10より大きい
解説: a=1, b=10として合計cを計算します。cが10より大きいから10いかをifで判断します。
条件分の最後は「:」で終わります。elseの後も同様「:」をつけます。
9. 繰り返し[forとwhile]
繰り返しコマンドを実行したい場合はforを使います。pythonではタブ(スペース)が重要な切れ目になっているので気をつけてください。また、for文の最後は「:」をつけます。これが終わりの合図です。
以下はfor文を使ってiを1から10までの範囲で繰り返すコードです。(実行結果は→)
for i in range(10):
i= i+1
print(i)
→
1
2
3
・
・
・
10
次に以下を実行してみてください。(実行結果は→)
for i in range(10):
i= i+1
print(i)
→
6
while文はプログラムでよく利用されるループコマンドの一つです。構文としては以下のようです。for文と似ています。
while 条件:
処理
例文は、初期値a=10で、aから1を引きくり返えして、aが0になったら終了です。これを実行すると以下のような出力が得られます。
a = 10
while a > 0:
print(a)
a -= 1
→
10
9
8
・
・
・
1
上のwhileの場合、aから1を引いていくので、いずれaは0となり、a>0という条件を満たさなくなり止まります。もし継続してループが続くような条件の場合、どのように停めたら良いのでしょうか?
そこで利用するのがbrakeです。そうコーヒーブレイクですね。white True:という無限ループを抜けるのがbrakeです。
以下のコードを見てください。randomモジュールをimportして、変数moneyの初期値を5とします。+=でrandom.randint(0,1)で乱数関数で0か1を発生してその2倍から1を引いたものつまり、1か-1を加えます。つまり一回ループが回るごとに1か(-1)が加えられることになります。そしてmoneyが0になったら負けで、10になったら勝ちですね。どちらかになるまでループが周り、どちらかになったらbreakで終わります。乱数を用いているのでやる度に結果が異なります。
(参考図書: )
※「#print(money)」の前の#を省くと途中のmoneyが出力されます。
import random
money = 5
while True:
#print(money)
money += random.randint(0,1)*2-1
if money == 0:
print(“負け”)
break
if money == 10:
print(“勝ち”)
break
10. 関数の定義と利用
pythonでも関数を定義して用いることができます。定義はdefコマンドです。いかに2つの関数を定義します。func(i)関数を2つの変数にiとi+1を入力すると定義しています。以下のコードではaとbにfunc(5)で数字を代入しています。また、add(a,b)関数をa+bの結果を返すと定義し、c=add(a,b)となっているので、a, b=func(5)でa=5, b= 6が代入され、c=5+6=11となり、a, b, cの出力は5, 6, 11となりますね。
def func(i):
return i, i+1
def add(a, b):
return a+b
a, b = func(5)
c = add(a,b)
print(a, b, c)
関数の中と外では定義(スコープ)された変数の挙動が異なります。次の例を見てみましょう。
a=10
def func():
a=20
print(a)
func()
print(a)
func()関数の中で定義されたa=20はすぐに出力され、最初にa=10で定義した値が最後にprint(a)で出力されます。つまりこの結果は20, 10になりますね。
関数内で利用する変数aをglobalとして定義すると、1行目に定義しているa=10は関数内のa=20で書き換えられてします。その結果出力は関数内の20と最後のprint(a)の20となり、20, 20という結果が出力されます。
a=10
def func():
global a
a=20
print(a)
func()
print(a)
「global a」でグローバル変数として定義しているので、最後の「print(a)」で処理されるaは20となって、20が出力されます。
11. データの型[リストとタプル]
データセットをまとめて扱う(取り込む)方法としてリスト(list)とタプル(tuple)があります。これは配列(array)として登録する方法と同じです。
初めにリストから説明します。
a=[1, 2, 3]やb=[“A”, “B”, “C”], c=[“5つの素数”, 1, 2, 3, 5, 7]といった1次元の配列に対して次の2次元配列を作ります。
d=[[1,5], [2,10]]
リスト変数の任意の要素を呼び出すにはa[2]として場所を指定します。
Pythonでは最初のデータ番地は0から始まります。aの場合だとa[0]=1, a[1]=2, a[2]=3となります。この[0], [1], [2]はインデンスクと呼びます。
次の行をコードに入力して実行してみてください。
a=[1,2, 3]
→ a[1]
a=[1,2,3]とb=[4,5,6]を使ってd=[a,b]のように、1次元配列を組みわせて2次元配列を作ることもできます。これは以下のように先にd=[]で空の変数dを定義しておき、appnedコマンドを使ってdに要素を追加しても同様に2次元変数dを定義できます。
a=[1,2,3]
b=[4,5,6]
d=[a,b]
d
→ [[1, 2, 3], [4, 5, 6]]
d=[]
d.append(a)
d.append(b)
d
→ [[1, 2, 3], [4, 5, 6]]
次にタプルがあります。リストと同じで配列を定義できます。以下の例を実行してみてください。配列を定義した変数は加算ができます。
a=1,2,3
b=(4,5,6)
c=a+b
c
→ (1, 2, 3, 4, 5, 6)
タプルは複数のデータを同時に変数に入力させるときに便利です。a=1, b=2としてa,bを同時に表示させることができます。
e=1
f=2
e,f
→ (1, 2)
特定のデータがデータ列の中の何番目にあるかを調べるときにenumerate(数を数えるという意味)を利用します。上の変数aを定義して、各要素の順番と変数を表示させましょう。
a=[1,2,3]
for i in enumerate(a):
print(i)
→
(0, 1)
(1, 2)
(2, 3)
12. ChatGPTでプログラミング
ChatGPTは2022年11月に一般に公開された自然言語処理によるAIシステムです。自然言語処理の生成型AI(Generative AIを生成AIと訳した)は、Deep Learningと言われる機械学習プログラムの一つで、transformerと言われるるプログラムを使っています。このプログラムでネット上の記事などの膨大なテキストを学修し(Large Language Model)、穴あき問題を繰り返し解いて続く言葉を探し当てる方法をとっていると言われています。膨大なテキストを学修した結果、飛躍的に言葉のやりとりを自然できるようになったと言われています(NECの広報ページ)。言葉の推論と同じようにして、プログラムの作成もできます。ネットには様々なプログラムが公開されていて、自然言語で作文するようにプロガラムをつくります。このためプログラミングのための文法知識は不要です。代わりに論理的で標準的な言葉の入力(プロンプト)で十分です。したがって、論理的かつ標準的な言葉を使える人々が多くの利益を受けることになります。Excelなどの関数の組み合わせも着くってくれます。Excelのセルをどのように使ってどのような結果を得たいかが明確でないと使うことができないのでExcelの関数のある程度の知識が必要です。
LLMはLarge Language Modelの略です。これは翻訳のためのプログラム(transformer)として取られたアルゴリズムですが、学習する文章の規模を大きくすることで急速にその翻訳の正解率が上昇しました。仕組みは、その前後の文脈でどのような単語が使われるかを予測します。学習した単語から穴埋め問題を際限なく解きます。その結果、次の単語が予測でき、それを次々行うと文章になるわけです。ですので正しい文法で文章を書くことができます。出力される内容は学習した文章の中から選択されるはずです。従って文脈上内容が正しいとは限りません。間違った内容が出力されることをハルシネーション(幻覚)といいます。これが拡散されることもあるので注意が必要です。また、ChatGPTの無料版では入力データを学修に利用し、他の出力に利用するらしく、極秘データを入れて公開されたということもあるようです。データを入力する場合は模擬データで置き換えて入力して、プログラミングだけを利用するようにしましょう。
では以下にChatGPTを利用してプログラミングしてみてください。
ChatGPTで1から10まで足すプログラムを書かせて見ましょう。ChatGPTは各自アカウントを作成しloginしてください。GoogleのBARDでもいいと思います(大学以外のアカウトでしか利用できません)。
ChatGPTに以下のように入れて見ましょう。
「pythonで1から10までを足すプログラムを書いてください」
そうすると以下のように表示されます。右上にプログラムをコピーする「copy code」をクリックしてコピーし、google colaboratoryのノートブックに+コードをクリックしてペースとしてください。
次に、この途中データをグラフにするpythonプログラムを作成して見ましょう。
「この途中データをグラフにするpythonプログラムを教えてください」
このコードを走らせたところエラーがでました。
そこで次のように入力しました。
「このgoogle colaboratoryで動くプログラムに変更してください」
これで折れ線グラフができました。是非試してみてください。
google アカウントではBARDというAIプログラムが利用できます。以下のように入れるとグラフを書くことができます。これですと、指定なしでもgoogle colaboratoryで動くプログラムを出力してくれます。
「1から10までを足し、途中経過をグラフにするpythonのプログラムを書いてください。」